Instagram kann mit mehreren Methoden auf dem PC aufgerufen werden. Sie können mit der Instagram-App in Windows 10, Android-Emulatoren, inoffizieller Software und der Instagram-Webversion auf Instagram zugreifen. Eine der besten Möglichkeiten, Instagram zu verwenden, ist die Verwendung der Webversion, die die Möglichkeit bietet, Direct, Beiträge und Story, zu senden und keine speziellen Add-Ons erfordert. Sie müssen lediglich den Chrome-Browser auf Ihrem Computer installieren. In diesem Text werden wir Ihnen die Verwendung von Instagram auf PC und Windows vorstellen und beibringen. Sie können Direct,Beiträge und Story, Likes und … ohne spezielle Software, senden.
Inhaltsverzeichnis Eine Einleitung in die Verwendung von Instagram in PC und Windows Lernen Sie, wie Sie Instagram auf dem PC im Desktop-Browser nutzen So senden Sie Post und Story auf Instagram mithilfe der Webversion von Instagram in PC und Windows Wie man Post auf Instagram über Computer sendet (PC) Wie man Story auf Instagram über Computer sendet
Eine Einleitung in die Verwendung von Instagram in PC und Windows
In der Vergangenheit konnten Benutzer, die die Webversion von Instagram verwendeten, nur einige Aktivitäten ausführen, z. B. das Anzeigen von Posts, das Like und Veröffentlichen von Kommentaren, das Suchen und Anzeigen von Benachrichtigungen, und nicht Direct und nachricht senden! Mit den jüngsten Updates von Instagram für seine Webversion ist es jedoch möglich, Bilder zu veröffentlichen, die Story auf eine persönliche Seite zu greifen Sie auf die Funktion Direct. Natürlich ist die Möglichkeit, Beiträge und Geschichten auf Instagram zu hinterlassen, für PC und Windows verborgen, und dazu muss der mobile Browsermodus in Windows verwendet werden.
In der Webversion gibt es jedoch standardmäßig eine Direct Funktion, und es ist wahrscheinlich, dass in naher Zukunft die Möglichkeit zum Senden von post und Story zur Webversion von Instagram im Desktop-Modus hinzugefügt wird.
Lernen Sie, wie Sie Instagram auf dem PC im Desktop-Browser nutzen
- Öffnen Sie den Chrome Browser auf Ihrem PC.
- gehen Sie zur Instagram Website.
INSTAGRAM.COM
- Loggen Sie sich dort mit Ihrem Konto ein.

- Instagram ist jetzt auf Ihrem PC verfügbar. Normalerweise sehen Sie oben rechts auf der Seite den „Benachrichtigungen“- Abschnitt, den „Explorer-Beiträge“- Abschnitt, die Startseite, die Profilseite und vor allem den Direct-Abschnitt, der für Nachrichten verwendet wird.
- Es ist auch möglich, Story und Posts anzuzeigen.


- Es gibt auch eine abschnitt zur Profilbearbeitung auf Ihrer Profilseite. Gespeicherte Beiträge und Einstellungen finden Sie auch im Menübereich.
- Eine der wichtigsten Funktionen, die der Webversion von Instagram hinzugefügt wurden, ist die Möglichkeit, zwischen zwei oder mehr Konten zu wechseln.

Wie Sie sehen, war es nicht möglich, Post und Story in der Webversion von Instagram zu senden, und um Post und Story zu senden, muss der Browser in den mobilen Modus geändert werden. Im Folgenden zeigen wir Ihnen, wie es geht.
So senden Sie Post und Story auf Instagram mithilfe der Webversion von Instagram in PC und Windows
- Öffnen Sie zunächst Ihren Google Chrome-Browser.
- Wenn Sie sich bereits bei Instagram angemeldet haben, melden Sie sich von Ihrem Konto ab.
- Drücken Sie dann STRG + UMSCHALT + I, um das Entwicklerfenster auf der rechten Seite des Bildschirms zu öffnen.
- Klicken Sie dann oben auf dem Bildschirm auf das Telefon- und Tablet-Symbol (neben den „Elementen“), um den Bildschirmmodus von Desktop zu Telefon zu ändern.
- Dadurch wird Instagram glauben, dass Sie die Webversion über Ihr Telefon eingegeben haben, und Sie können Post und Story senden.
- Klicken Sie nun links auf „Anmelden“.
- Geben Sie in diesem Schritt Ihren Benutzernamen und Ihr Passwort ein und klicken Sie auf „Anmelden“.



Wie man Post auf Instagram über Computer sendet (PC)
- Klicken Sie auf das Symbol (+) unten auf der Seite, um einen Post zu senden. Dann öffnet sich ein Fenster und Sie können Ihr gewünschtes Foto auswählen und einen Post senden, der der Android Instagram App ähnelt.

Wie man Story auf Instagram über Computer sendet
- Um eine Story zu senden, klicken Sie oben auf der Seite auf das Kamerasymbol (siehe Abbildung unten). Wählen Sie dann das gewünschte Foto aus. Jetzt können Sie einen Text für Ihre Story schreiben und schließlich klicken Sie unten auf der Seite auf „Zu Ihrer Story hinzufügen“, um Ihre Story zu senden.

Was ist Ihre Meinung zu diesem Tutorial?
Wir hoffen, dass Sie dieses Tutorial hilfreich finden. Wenn Sie Probleme oder Fragen haben, senden Sie uns einen Kommentar im Kommentarbereich, dann werden wir Ihnen antworten.
Zusammenhängende Posts:
 Wie Sie Post (Fotos und Videos) in der Instagram-App senden
Wie Sie Post (Fotos und Videos) in der Instagram-App senden
 Bilaterale Nachrichten löschen oder Unsend in Instagram Direct
Bilaterale Nachrichten löschen oder Unsend in Instagram Direct
 Erfahren sie, wie sie benutzer anzeigen, unsere Story anzeigen
Erfahren sie, wie sie benutzer anzeigen, unsere Story anzeigen
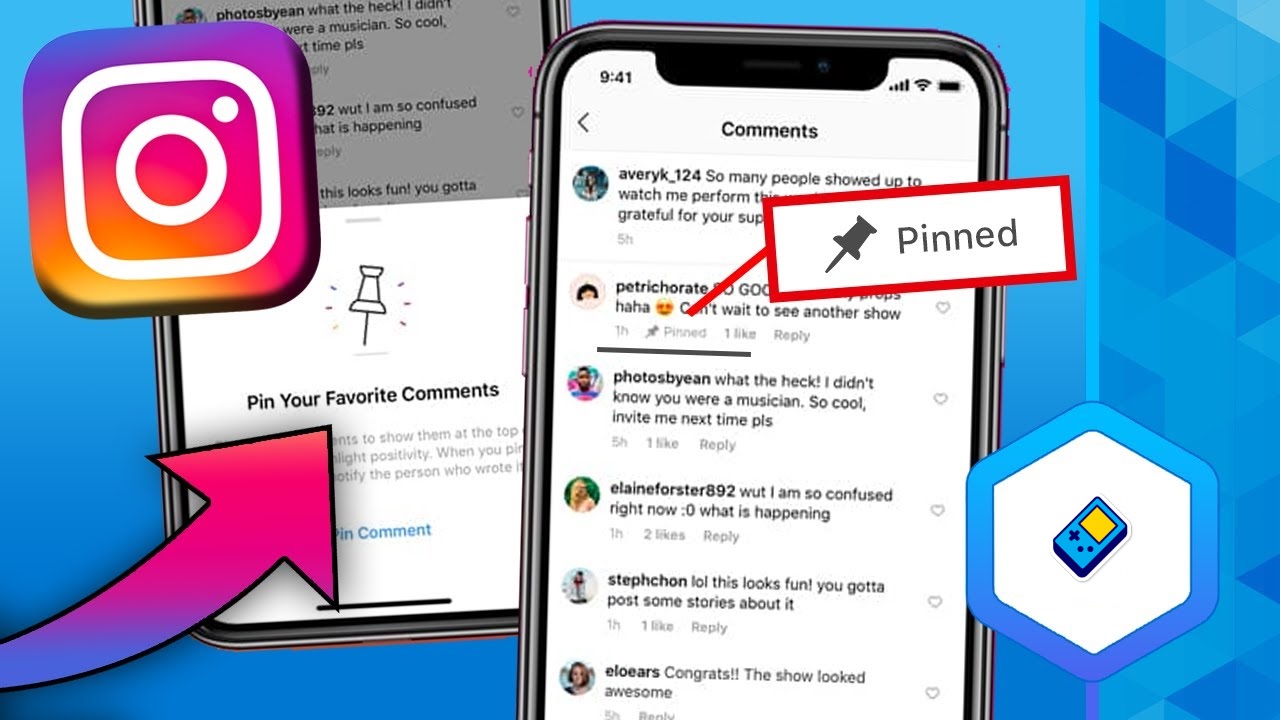 Wie man einen Kommentar auf Instagram fixieren kann
Wie man einen Kommentar auf Instagram fixieren kann
 Wie Sie Ihren Instagram-Account dauerhaft löschen
Wie Sie Ihren Instagram-Account dauerhaft löschen
 wie Sie Ihre Instagram-Aktivität oder Ihren Online-Status verbergen
wie Sie Ihre Instagram-Aktivität oder Ihren Online-Status verbergen
 Instagram-Datenverbrauch reduzieren, sparen Internetpaketen
Instagram-Datenverbrauch reduzieren, sparen Internetpaketen
 Wie lösen sie fehler „Leider hat Instagram aufgehört“ in Android
Wie lösen sie fehler „Leider hat Instagram aufgehört“ in Android
 Wie Sie das Windows 10 Emoji in Browsern und Word verwenden
Wie Sie das Windows 10 Emoji in Browsern und Word verwenden